
 فارسی
فارسی
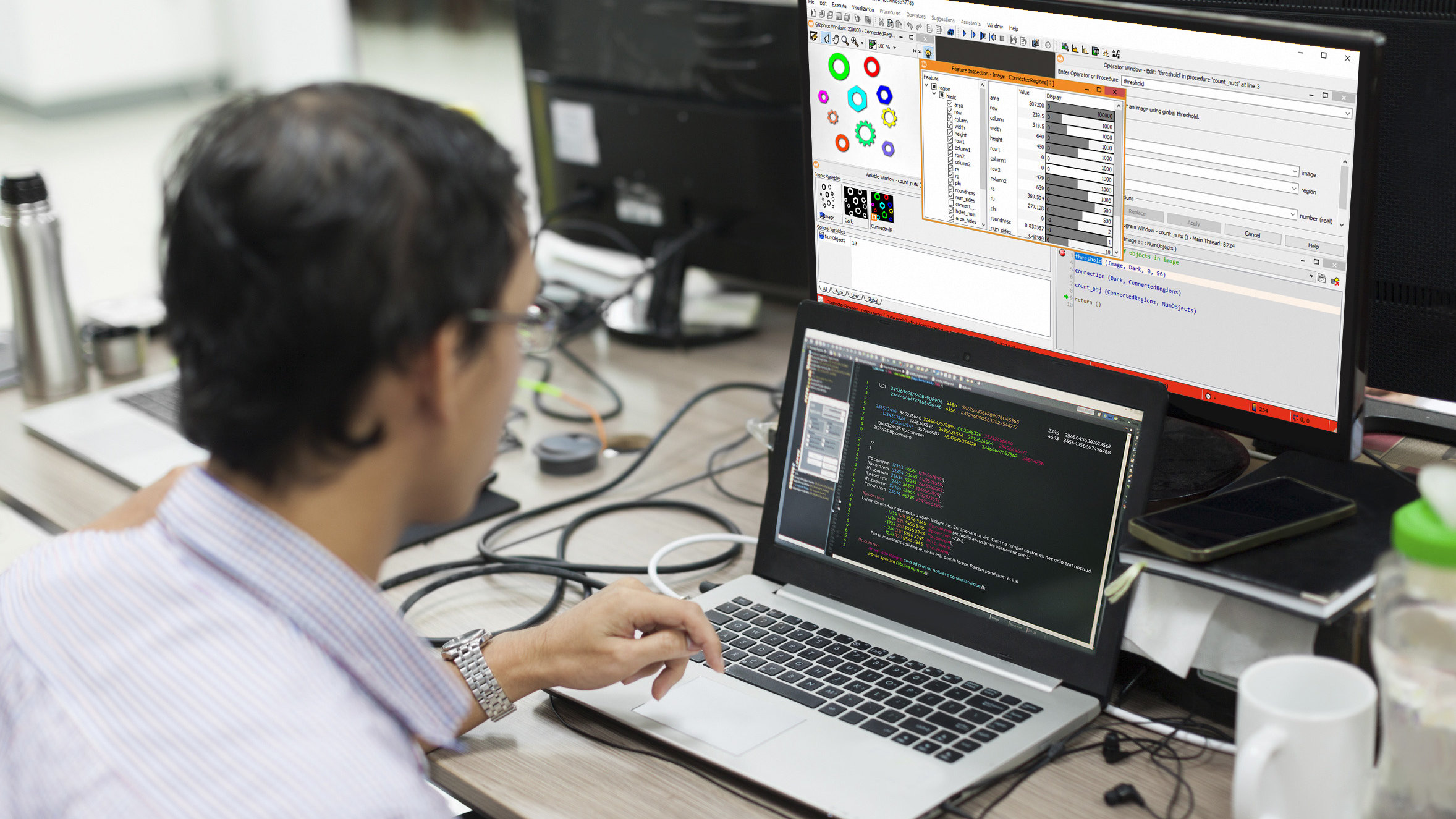


What is Object Detection in Image Processing?
Object Detection is an image processing algorithm used to locate objects within an image. For this algorithm to identify an object, a model of that object needs to be created. In the next stage, the algorithm starts searching the image. The object detection algorithm searches the image to find the desired model. When the algorithm identifies an object, it means that the detected model matches the target model.
The object detection algorithm in image processing is widely used, and its implementation can support various industrial image processing projects. The algorithm has applications in other algorithms such as optical character recognition and measurements. This article explores the main idea and results of using this algorithm in image processing. Another article will delve into the Applications of Object Detection in Image Processing. To implement the object detection algorithm, you can use the powerful HALCON software developed by MVtec. The images in this article showcase examples of implementing this algorithm in the HALCON software, where the object detection algorithm is referred to as “matching.”
To enroll in the “Machine Vision Training Course with HALCON software,” click here.
Purpose of Object Identification and Detection in Image Processing
In the object identification algorithm, the goal is to find an object, meaning searching for something in the image to locate it. By finding an object, we mean determining its pixel coordinates on the image. Calibration may be needed to transform these pixel coordinates into real-world coordinates. Finding an object in image processing can serve various purposes, such as reporting piece coordinates to other equipment (like robots), identifying the position of an object in tracking systems, identifying the number and types of different models, and many other applications, some of which are discussed in Applications of Object Detection in Image Processing.

For your projects, you can consult with our experts here.
Main Idea of Object Detection in Image Processing
The working mechanism of the matching algorithm (object detection) in image processing is as follows: first, define a model as a reference in it. Then, search for it. Matching consists of two main stages: model creation and model finding.
Stage One: Creating a Model for Object Detection
Model creation: Suppose the goal is to find an IC in different images. The image used to create the model is called a reference image. Depending on different algorithms, the model can be based on edges, pixels, or points. As seen in the image, the goal here is to find an IC in various images, and the matching model is created based on edges.
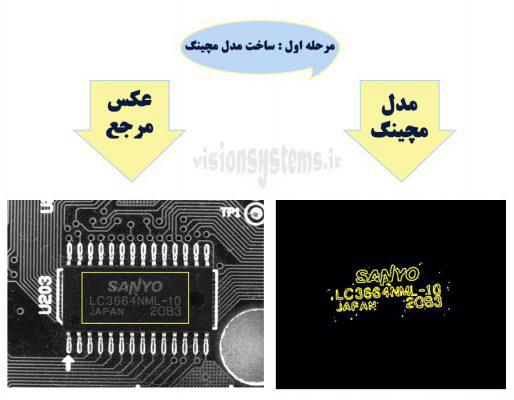
Stage Two: Object Identification
In this stage, search for the model in various images. This model is the one created in the previous stage. As shown in the images below, the desired object is found in different images using the created model.

Output of the Object Detection Algorithm in Image Processing
The output of the algorithm includes:
1. Object Coordinates
For example, the object detection algorithm in the image below tells us that the piece’s center is at the specified points on the image. Object detection algorithms can represent coordinates in pixel units. If needed, these coordinates can be transformed into real-world coordinates. Consider the image below, where we are looking for specific piece holes, and matching provides us with pixel coordinates. An example of announcing real-world coordinates by matching is provided in the next section.

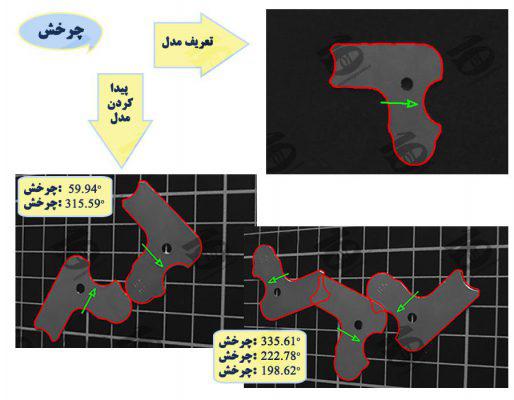
2. Rotation
The object detection algorithm can tell us how much an object has rotated. Rotation is defined as an angle between 0 to 360 concerning the original model. For example, after defining the original model, real-world coordinates, and body rotation in the images, are visible.
3. Scale
The enlargement or reduction of an object concerning the original object can be defined as a number in some object detection algorithms. For example, in the image below, observe the enlargement or reduction in terms of length and width relative to the original model. If this ratio is more than one, it means enlarging the model relative to the original model, and if it is less than one, it means reducing the model relative to the original model.
